本文共 4823 字,大约阅读时间需要 16 分钟。
2020年无疑是特别的,我们在不平凡的这一年,经历着开局的艰难,以及随之而来的各种变化和冲击。好在,我们终于可以跟充满问号的2020年说“再见”啦。
今天是2021年第一天,不知道大家对于过去有哪些收获与感悟,又将在新的一年里定下了什么样的小目标呢?
从云技术发展来看,2020随着企业上云旅程的深入和数字化转型的加快,“云原生”这个词开始频繁出现在我们耳边。什么是云原生?如何开发云原生应用?会涉及哪些云服务?又能给企业带来什么价值?值此新年之际,我们一起定个新年新目标:打造自己的首个云原生应用!
云原生系列内容预计分为五个章节,内容涉及云原生应用初识,将Spring Cloud服务升级为Kubernetes,云原生应用的流量治理,微软云容器服务AKS 详解,基于多种云原生应用的服务区别和使用场景介绍。
本篇,我们先和大家一起谈谈云原生应用是什么,以及如何成为合格的云原生应用公民。

作为云方案架构师,我们经常遇到一些客户抱怨:“我们系统上云了,之前的问题感觉并没减少,并且还遇到新出现的问题,感觉上云就是一个大坑”。
造成这种情况的原因很多,可能无法一一列举,但成功的案例确有遵守着一些准则。云原生对应用架构最大的影响是服务不应该仅仅止步于云化。如果仅将服务迁移上云,而对服务本身的架构没有进行云化适配改造,那么服务上云的收益就无法最大化。云原生应用架构的诉求是最大程度利用云基础设施的优势,且应用自身架构也要升级。希望通过以下分享,能为大家构建成功的云原生应用提供参考,同时对已经在云上运行,但遇到问题的童鞋提供明确方向,了解应该在哪方面改进或优化。
何为云原生?
“所谓云原生应用,就是完全基于云计算资源而设计的应用,即为云而生,并可在所有云平台上无缝移植运行的应用。”
——Pivotal公司的Matt Stine于2013年
云原生化的路线图中包括如下技术栈:

根据CNCF对云原生的定义,云原生技术是通过一系列软件、规范和标准,帮助企业和组织在现代化云计算架构体系(公有云、私有云和混合云)中构建和运行敏捷、可扩展应用程序的一整套技术栈。根据这个定义,对上述十点,在实践经验进行总结简化的话,可以归纳为如下四点:
-
容器及其编排引擎
-
微服务及其治理
-
声明式API等都是极具代表性的云原生技术
-
DevOps
CNCF同时也提供了一些对应技术栈和供应商的全景图,主要帮助大家在选择技术和服务的时候提供一些参考和推荐。如下:
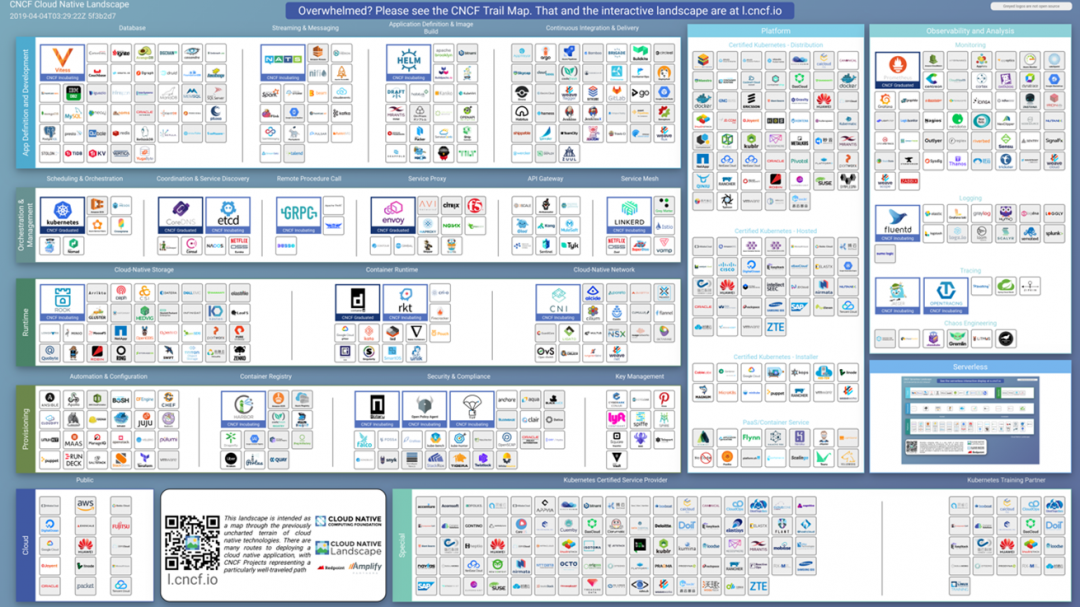
上述全景图将CNCF定义的云原生生态圈划分为“五横两纵”。
“五横”
1)应用定义与开发;
2)编排与治理;
3)运行时;
4)应保障;
5)基础设施;
“两纵”
1)PASS平台;
2)监控观察与分析;
全景图中包含经过CNCF社区认证的较为成熟或使用范围较广、具有最佳实践的产品和方案,试图从云原生的层次结构及不同的功能组成上让用户了解云原生体系的全貌,并帮助用户在不同的云原生应用实践环节选择恰当的软件和工具来实现。
微软云作为其中的一员,对各个部分也提供了自己的组件:
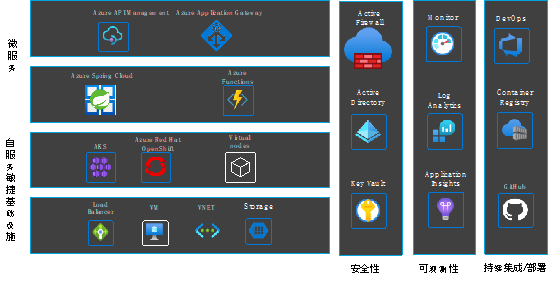
上述内容相信能让大家对云原生实施步骤和技术栈有更清晰的认识。大家可对照这些步骤和技术,检查已有应用架构,看自己的应用在哪些方面有所欠缺,做相应的补足和加强,让自己的应用成为合格的云原生应用。
合理微服务化
大家在日常生活中都会听到“微服务”这个词,但它并没有出现云原生的路线图十条范围内。其实微服务是云原生应用的前提和基础,无论基于成本还是效率等考虑都要先微服务化。缺乏有效的微服务化,云原生的很多能力都是空谈。
没有进行合理微服务化的服务,可以称为单体应用或巨石应用,在弹性扩展的时候需要消耗更多资源,同时涉及的业务也可能过于复杂等等。
服务可从三个维度进行扩展:
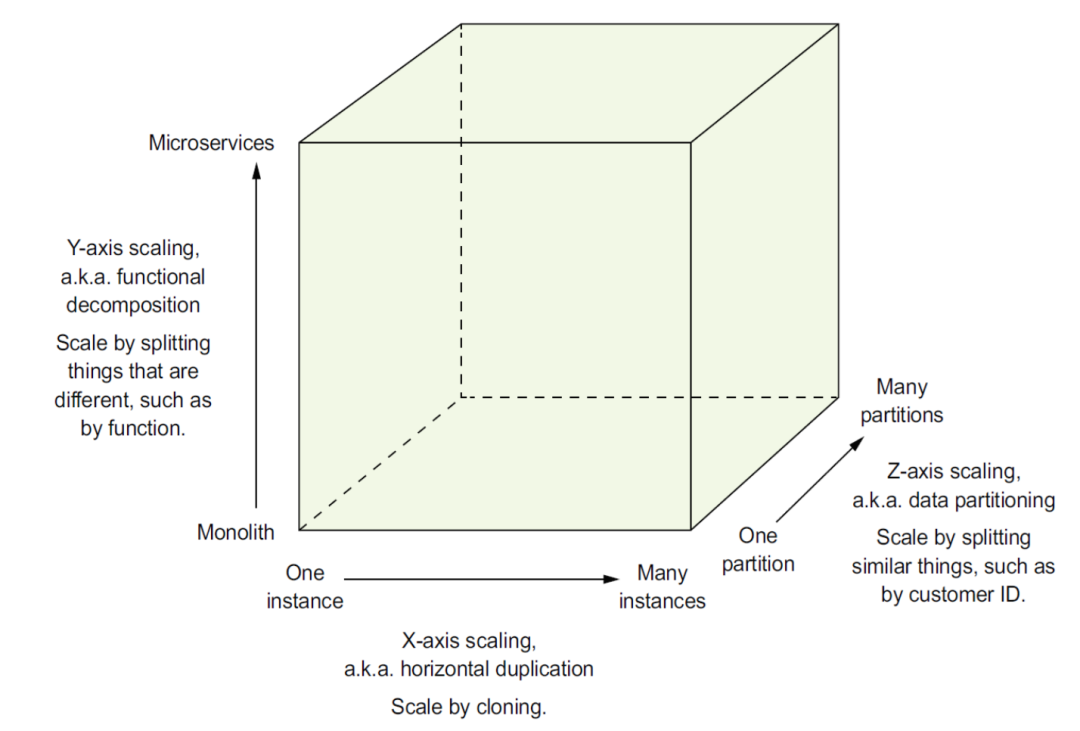
X轴:一个变成多个(水平扩展,通过负载均衡来实现选择)
Y轴:根据业务模块来拆分(垂直拆分扩展,实现微服务化)
Z轴:数据拆分(通过数据分区,分库分表来实现对热点数据和服务的进一步拆分)
上面提到一个词,就是合理微服务化。微服务化怎么做到合理呢?
大家都知道,典型的四件套LAMP(Linux、Apache、MySQL、PHP)在项目初期通常就采用这类单体架构。在项目初始阶段,这种架构的性价比是非常高的,开发速度快、成本低,一台廉价服务器就能跑起来。单体架构也会带来很多问题,例如项目复杂性高,模块组件边界模糊、依赖不清;扩展能力有限,不能按需伸缩,只能以整体方式进行扩展。
受所使用的技术平台和语言限制,单体架构通常是技术创新的绊脚石,很难在单体架构上进行应用创新;随着系统功能和开发人员的增加,单体架构积累的技术债务会越来越多。因此单体架构越来越被诟病,慢慢选择微服务的方式来开发和运维。
微服务到底要做到多“微”才算合理,是不是把服务拆得越细越好?![]()
先看看这个光谱图:

理论上我们在Y轴业务模块上,把功能拆成一个个function单元,在Z轴上把数据让没一条记录放在一个库一个表里面,显然从成本和运维的角度来考量是不现实的。
所以要有一套方法来指导我们拆分,这就是领域驱动设计(Domain Driver Design)。领域驱动设计的核心是设计出一套核心的领域模型(Domain Model)还表达和承载业务。
领域(Domain):为了执行用户的某项活动,或是满足用户的某种需求。这些用户应用软件的问题区域就是软件的领域。
模型(Model):模型是一种简化。它是对现实的解释——把与解决问题密切相关的方面抽象出来,而忽略无关的细节。
领域模型(Domain Model):为设计人员,开发人员和用户使用一种公共语言,使得所有团队成员可以使用这些术语来讨论模型和设计决策。
比如我们讨论去哪里的时候,这是一个出行问题,是我们现在的领域。模型在这里可以认为是地图,如果要建立合适的领域模型,我们可以借助地图来框定出行的范围。如果从上海到美国拉斯维加斯,我们可能要引入航空公司、航班以及中转站等。而如果从上海到南京,可能要引入高铁、长途汽车等;而如果要从上海公司地址到附近地铁站的话,就只需要共享单车或步行等方式了。
确定了这些术语之后,我们再结合地图来阐述出行方式,这样问路人和指路人就能很好的沟通,而且是一个可行方案。
在实际场景中,就是识别出一个个问题的上下文,基于这个上下文确定模型,然后通过模型来阐述一个个业务场景。
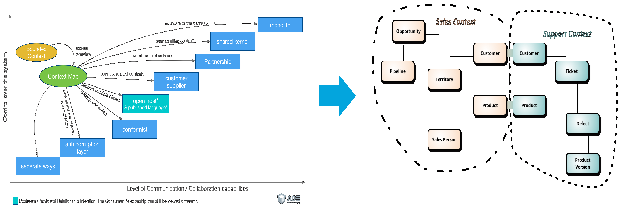
在微服务的定义里,早期也有个比较形象的理论:一个微服务的开发负责人,一个披萨就可以吃饱,具体下来就是一个微服务可能只需要三四个人来开发。通过这种比较小的团队也可以和业务和用户快速沟通。
通过上述方法和介绍,大家可以结合自己的业务和团队去思考如何合理拆分服务,最后形成高效的开发运维方式,输出更多的业务价值。
有了云原生和微服务的介绍,相信大家会有一些概念,有想把已有系统改造的念头和冲动。在动手之前,还有一些重要因素需要注意。
1. 服务流量
由于服务拆分后,服务间的调用变得更复杂,同时调用也分成服务集群外来调用(称为外部流量或南北流量)以及系统内部之间的调用(称为内部流量或东西流量)。
由于每个服务对业务重要性可能不同,为了更好地保证稳定性和核心功能可用性,在微服务中,一般用限流、熔断降级和故障模拟三种方式来应对和测试。
限流很好理解,一般就是在南北流量入口,类似网关的地方做流量限制配置,操作一定数之后,就直接拒绝,保证进入系统的流量是一个预计和可控的。
限流一般有三种算法:
-
计数器:单位时间内,累计到达一定数量,后面的请求全部拒绝。
-
漏桶:通过队列保存请求,通过线程池从队列中获取请求,一次性获取多个并发执行。
-
令牌桶:通过队列用来保存令牌,通过一个线程池定期生成令牌放到队列中,每来一个请求,就从队列中获取一个令牌,并继续执行。
服务熔断:当下游服务因某种原因突然变得不可用或响应过慢,上游服务为保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。熔断主要做错误隔离,防止调用链路的服务雪崩。
熔断分成三个状态:
-
Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制。
-
Open:熔断器打开状态,此时对下游调用都内部直接返回错误,不走网络或降级。
-
Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态。
最后就是故障模拟(Chaos Monkey),也叫做混沌测试,通过引入一些已知和未知的问题来考验系统的稳定性,把一些已知的情况确定下来,把一些未知变成已知。
2. 服务监控
服务监控主要是为了达到如下效果:
-
趋势分析:长期收集并统计监控样本数据,对监控指标进行趋势分析。
-
对照分析:随时掌握系统不同版本在运行时资源使用情况差异,或在不同容量环境下系统并发和负载的区别。
-
告警:当系统即将或已出现故障时,监控可迅速反应并发出告警。这样管理员就可提前预防问题发生或快速处理已产生的问题,从而保证业务服务的正常运行。
-
故障分析与定位:故障发生时,技术人员需要对故障进行调查和处理。通过分析监控系统记录的各种历史数据,可以迅速找到问题的根源并解决问题。
-
数据可视化:通过监控系统获取的数据,可以生成可视化仪表盘,使运维人员能够直观地了解系统运行状态、资源使用情况、服务运行状态等。
通常情况下,监控系统分为端监控、业务层监控、应用层监控、中间件监控、系统层监控这5层。对应的开源框架如下图:
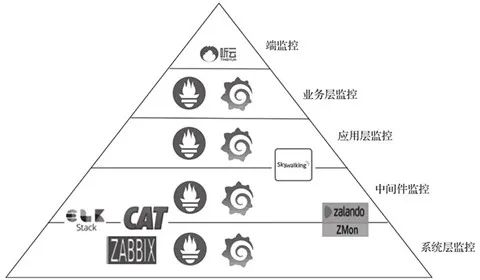
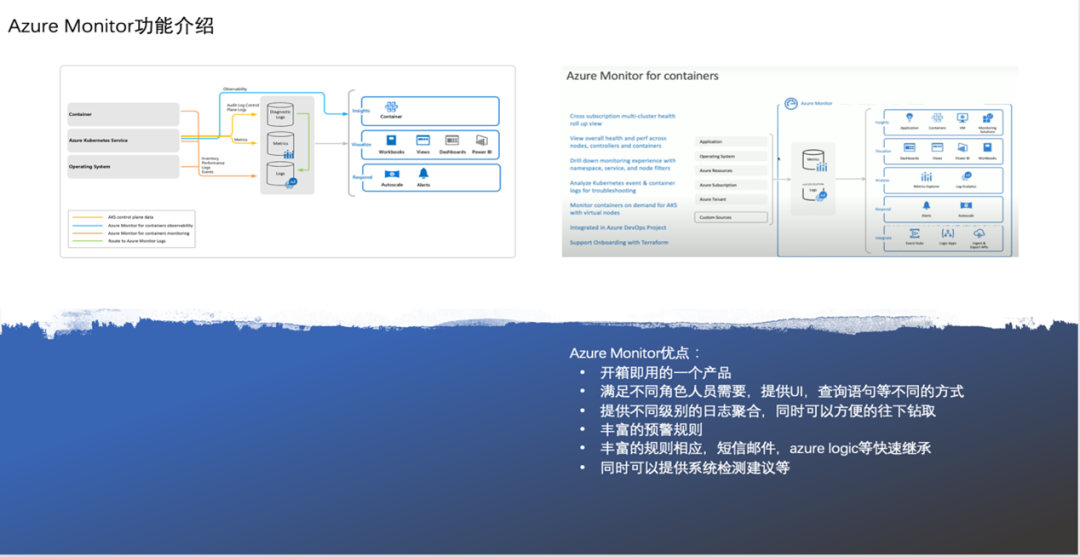
而在Azure上通过Application Insight和Azure Monitor即可实现这五层的所有监控能力,并将监控数据整合在一个业务中供查询和使用。
3. 性能
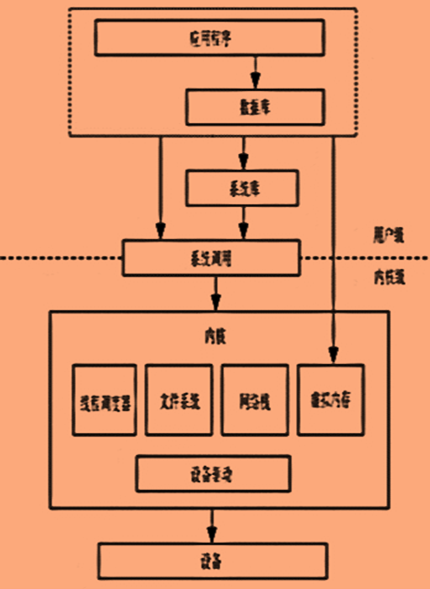
一旦遇到性能问题,很多人往往感觉束手无策,不知道从哪里着手。虽然性能问题很难处理,但总结起来主要有如下几点原因:
-
涉及技术栈广
-
涉及角色众多:系统管理员、应用开发者、数据库管理员、网络管理员、运维人员、测试人……
-
对应的工具与指标度量众多
那么性能问题该怎么处理?大致可以分成三个阶段:设计阶段、开发结算、测试和运维阶段。每个阶段处理的方法和工具会有一些不同
《黄帝内经·素问》中提到:“是故圣人不治已病治未病,不治已乱治未乱,此之谓也。” 其实程序设计也一样,要把很多问题在设计阶段就规避掉,如果让问题发生到后期,需要的人力和物力会成本增长。所以在设计阶段要做好:
-
通过前面介绍的DDD原则来拆分成一个个无状态化服务
-
识别出系统性能可能瓶颈件,确定系统性能指标
-
确定硬件和中间件规格,在相应的资源之上进行BenchMark测试
-
架构的确定(比如采用前端分离等架构,让各自模块最大化优化)
-
对关键组件进行POC
而在开发阶段需要注意:
-
加强核心代码的Performance review
-
结合CI/CD把性能测试和代码改动提交结合起来
-
建立完整监控体系,并加以运用
在测试和运维阶段,需要结合前面讲的监控技术建立灵活的预警系统,应对不同场景的需求,比如秒杀等。借此形成有效问的题响应机制,使用统一的性能描述语言来沟通问题,并利用日志和系统工具得到最多的第一现场信息,实现快速锁定和分析问题所在。
最后,为了更好的用户体验,一般可对前端采用如下几点作为优化内容:
-
前后端分离
-
单页面应用
-
使用最新前端技术比如ReactJs或者VueJs等
-
使用异步加载和Virtual Model等
-
通过JavaScript函数语言特性,使用方法缓存
-
通过浏览器Performance工具和Console得到性能数据
-
通过CDN等加速
以上是本次分享的全部内容,主要从设计和概念角度进行阐述和说明。云原生是个很大的概念,后续我们还将通过更多文章分别进行介绍,敬请期待。
最后,祝大家新年快乐 !
转载地址:http://dnrtf.baihongyu.com/